At the WZB, as part of a project on the AfD (the new radical right party in Germany), I recently had to analyze CVs of Members of the Bundestag. The idea was to automatically download the MPs’ profiles from the Bundestag website using web scraping techniques and then to describe the social structure of the AfD faction using quantitative and qualitative methods. I was particularly interested in the prior political experience of the AfD representatives. Extracting this type of information automatically is difficult and I opted to code some of the material manually.
I was looking for a tool to work with the data collected. In social sciences, ATLAS.ti, MAXQDA, and NVivo are the most commonly used programs to analyze qualitative data. Yet, these programs are expensive and not everyone is able to afford a license. Also, I simply did not need all the bells and whistles offered by these tools (I suspect I am not the only one in this situation).
The essence of qualitative data analysis (QDA) is to annotate text using relevant codes. Think of a computer-assisted qualitative data analysis software (CAQDAS) as a super highlighter (your brain is still doing the hard stuff). The rest – extracting content from PDF files, combining codes, visualizing them, etc. – can be performed by other programs. These functions do not have to be necessarily bundled with QDA programs.
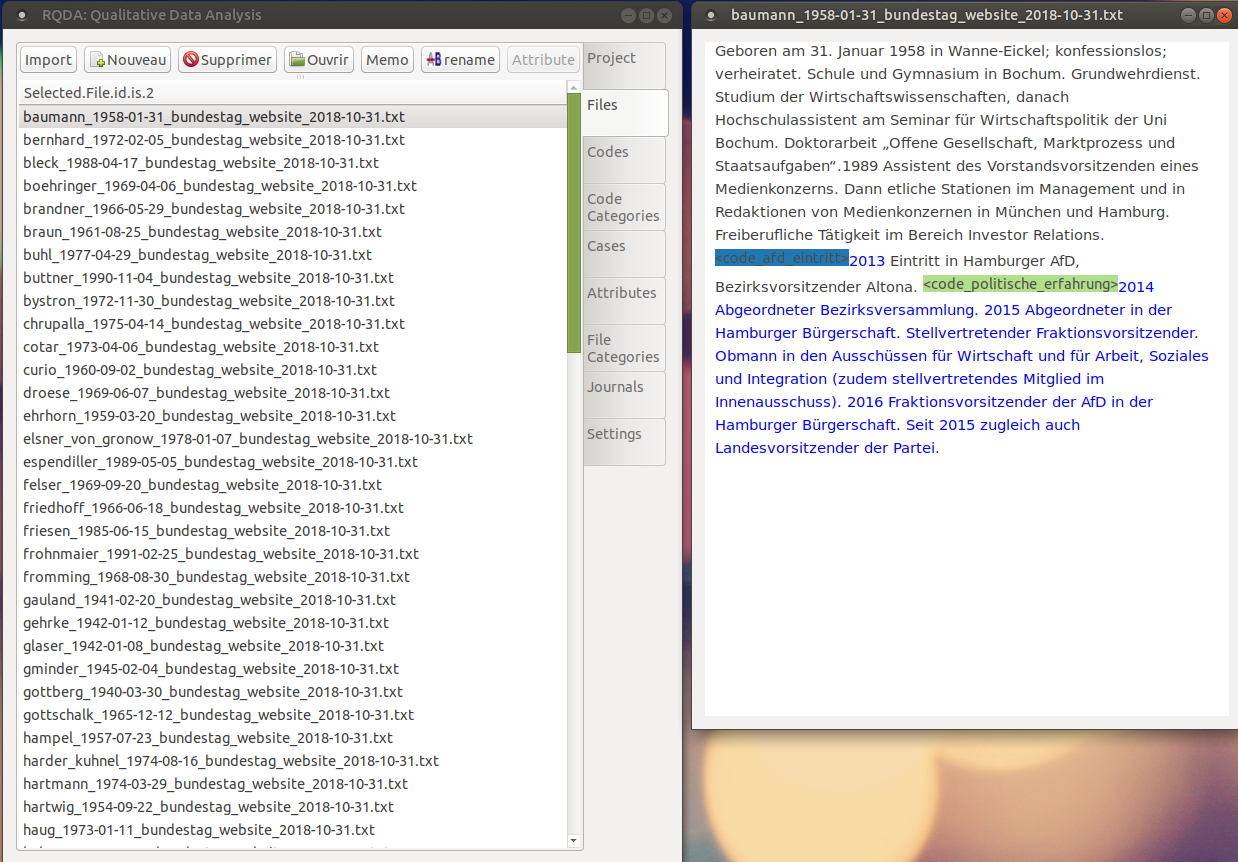
I took a look at RQDA, a free, light, and open-source CAQDAS built on top of R. RQDA was designed by Ronggui Huang from Fudan University, Shanghai, and has been used in a number of publications. The package is still in development (current version 0.3-1) and some bugs are apparent. Yet, RQDA does the essential right. It allows you to import text files (in many languages), code them using a graphical interface, and store your codes (and their meta-information) in a usable format.
What I find particularly exciting about RQDA is that it lets you use the powerful machinery of R. Compared to other programs that work with closed software environments, RQDA is highly expandable. Think of all the R packages available to manipulate, analyze, and visualize textual data. Combining qualitative and quantitative data is also really easy, which makes RQDA a very good tool for mixed methods.
Most importantly, since RQDA is free and open-source, anyone with an Internet access can download R and RQDA and reanalyze coded texts. Sometimes qualitative data contains sensitive information and it is not advisable to share it. Yet, often, scholars analyze data that is already public (as I do). In this case, it might be interesting to put your coding schemes online.
Researchers usually agree that quantitative methods should be reproducible. This means that it should be possible to reproduce the findings of a publication (tables and figures) by re-running code on the raw data. I argue that qualitative research, when it does not use sensitive data, should be traceable, in the sense that others should have the possibility to go back to the source texts, examine the context, and reinterpret the coding. Simply by being free and open source, RQDA facilitates the diffusion and reuse of qualitative material and makes qualitative research more traceable.
There are good RQDA tutorials online, especially the Youtube series prepared by Metin Caliskan, in French and English (see also, Chandra and Shang 2017; Estrada 2017). I learned a lot from these demonstrations and made good progress with the coding of the CVs of the members of the Bundestag. I am really satisfied with RQDA and, for the moment, do not feel the need to move to proprietary software.